以下的内容来自于LLaMAgithub仓库与Huggingface中的LLaMA实现。
结构
llama的结构自始至终没有什么改变,无非就是每一代都把GQA的实现下放到小参数上。
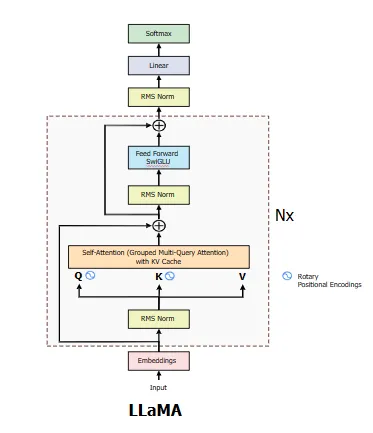
大体的结构和GPT-2还是非常相似的,Decoder-only,前置Norm等等。具体结构可见下面的代码:
class LlamaModel(LlamaPreTrainedModel):
"""
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`LlamaDecoderLayer`]
Args:
config: LlamaConfig
"""
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.padding_idx = config.pad_token_id
self.vocab_size = config.vocab_size
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
self.layers = nn.ModuleList(
[LlamaDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
self.norm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = LLAMA_ATTENTION_CLASSES[config._attn_implementation](config=config, layer_idx=layer_idx)
self.mlp = LlamaMLP(config)
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
class LlamaForCausalLM(LlamaPreTrainedModel):
_tied_weights_keys = ["lm_head.weight"]
def __init__(self, config):
super().__init__(config)
self.model = LlamaModel(config)
self.vocab_size = config.vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()Embedding
没什么好说的,BERT同款,可训练的Embedding。
Decoder Layer
Decoder Layer主要由注意力层,MLP与RMSNorm组成。前向传播代码如下:
residual = hidden_states # 1. 保留残差x
hidden_states = self.input_layernorm(hidden_states) #2. 计算前置RMSNorm
#3. Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
cache_position=cache_position,
**kwargs,
)
# 4. 计算残差
hidden_states = residual + hidden_states
# 保留残差
residual = hidden_states
# 6. MLP之前的RMSNorm
hidden_states = self.post_attention_layernorm(hidden_states)
# 7.计算MLP
hidden_states = self.mlp(hidden_states)
# 8.计算残差
hidden_states = residual + hidden_states
outputs = (hidden_states,)
# 是否输出Attention Weight
if output_attentions:
outputs += (self_attn_weights,)
# KV Cache
if use_cache:
outputs += (present_key_value,)
return outputsRMSNorm
原论文地址:https://arxiv.org/pdf/1910.07467.pdf
总结一下就是省略计算mean的操作不会影响性能,但可以节省大量计算开销。
作为对比,我们首先回顾一下LayerNorm。 \[ y = \frac{x-E(x)}{\sqrt{var(x)+\epsilon}} \]
其中x为对应dim上的一组数。
代码如下:
class LayerNorm(nn.Module):
def __init__(self,d_model,eps=1e-12):
super().__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = 1e-12
def forward(self,x):
var,mean = torch.var_mean(x,dim=-1,keepdim=True)
out = (x-mean) / torch.sqrt(var+self.eps)
out = self.gamma * out + self.beta
return outLayerNorm通过归一化处理,防止每一层的分布发生剧烈变化,减少Internal Covariate Shift,让分布趋于稳定,使得梯度传播更加稳定,有助于减少梯度消失和梯度爆炸。也减少了对训练数据分布的依赖,提高模型的泛化能力。
RMSNorm全名为 Root Mean Square Norm,去除了LayerNorm中的均值部分,包括分子中减去均值的操作和分母中计算方差时减去均值的操作。也就是说,分母变成了均方根。 \[ y = \frac{x}{RMS(x)} ,RMS(x) = \sqrt{\frac{\sum_{i=1}^Nx_i^2}{N}} \]
class RMSNorm(nn.Module):
def __init__(self,d_model,eps=1e-12):
super().__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
def forward(self,x):
rms = x.pow(2).mean(dim=-1,keepdim=True)
out = x * torch.rsqrt(rms + self.eps)
return self.gamma * out + self.betaAttention
Attention可选三种。
LLAMA_ATTENTION_CLASSES = {
"eager": LlamaAttention,
"flash_attention_2": LlamaFlashAttention2,
"sdpa": LlamaSdpaAttention,
}其中LlamaAttention与LlamaSdpaAttention的计算相同,后者使用了torch官方的sdpa
API。而LlamaFlashAttention2是对FlashAttentionV2的实现。我们这里只看LlamaAttention。
class LlamaAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: LlamaConfig, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
self.layer_idx = layer_idx
if layer_idx is None:
logger.warning_once(
f"Instantiating {self.__class__.__name__} without passing a `layer_idx` is not recommended and will "
"lead to errors during the forward call if caching is used. Please make sure to provide a `layer_idx` "
"when creating this class."
)
self.attention_dropout = config.attention_dropout
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_key_value_heads = config.num_key_value_heads
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.max_position_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
self.is_causal = True
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {self.num_heads})."
)
# 注意,这里只有Q是完整的4096×4096维,而KV都是1024×1024维
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.o_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=config.attention_bias)
self._init_rope()在初始化中,大体和原始的Attention是一样的。区别的地方在于使用了GQA,所以KV的head数与Q会不同。
在llama3-8B中,完整的config如下:
{
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128009,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 8192,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.40.0.dev0",
"use_cache": true,
"vocab_size": 128256
}可以看到Q的head数是32,每一个head包含128维的向量。而KV的head数只有8,意味着每4个Q为一组,共享一组KV。
在计算Attention
Score之前,需要计算出旋转矩阵,与输入的x相乘。由于默认情况下,rope_scaling=null,所以会采用最普通的旋转矩阵。

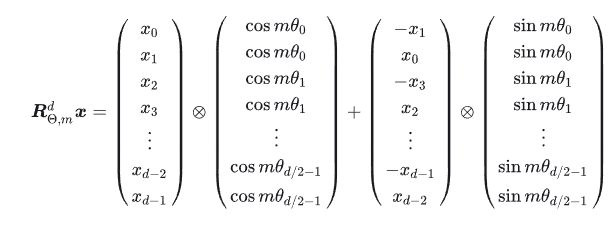
class LlamaRotaryEmbedding(nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
super().__init__()
self.scaling_factor = scaling_factor
self.dim = dim # head_dim = 128
self.max_position_embeddings = max_position_embeddings
self.base = base # θ
# 10000^(i/d) i = [0,2,4,...,126]
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
# 最大序列长度为8192
self.max_seq_len_cached = max_position_embeddings
# 公式中的m,也就是pos
t = torch.arange(self.max_seq_len_cached, device=device, dtype=torch.int64).type_as(self.inv_freq)
t = t / self.scaling_factor
# 计算外积,也就是[pos*10000^(i/d)],其实就是cos与sin中的角度
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
# 在最后一维进行拼接 [seq_len,2*head_dim]
emb = torch.cat((freqs, freqs), dim=-1)
# 登记cos(emb)与sin(emb),也就是cosmθ与sinmθ
self.register_buffer("_cos_cached", emb.cos().to(torch.get_default_dtype()), persistent=False)
self.register_buffer("_sin_cached", emb.sin().to(torch.get_default_dtype()), persistent=False)
@torch.no_grad()
def forward(self, x, position_ids):
# x: [bs, num_attention_heads, seq_len, head_size]
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
position_ids_expanded = position_ids[:, None, :].float()
# Force float32 since bfloat16 loses precision on long contexts
# See https://github.com/huggingface/transformers/pull/29285
device_type = x.device.type
device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
with torch.autocast(device_type=device_type, enabled=False):
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos()
sin = emb.sin()
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
"""Applies Rotary Position Embedding to the query and key tensors.
Args:
q (`torch.Tensor`): The query tensor.
k (`torch.Tensor`): The key tensor.
cos (`torch.Tensor`): The cosine part of the rotary embedding.
sin (`torch.Tensor`): The sine part of the rotary embedding.
position_ids (`torch.Tensor`, *optional*):
Deprecated and unused.
unsqueeze_dim (`int`, *optional*, defaults to 1):
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
Returns:
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
"""
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed下面看前向传播。
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Cache] = None,
output_attentions: bool = False,
use_cache: bool = False,
cache_position: Optional[torch.LongTensor] = None,
**kwargs,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()
# 关于张量并行的内容
if self.config.pretraining_tp > 1:
key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
query_slices = self.q_proj.weight.split(
(self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0
)
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
query_states = torch.cat(query_states, dim=-1)
key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
key_states = torch.cat(key_states, dim=-1)
value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
value_states = torch.cat(value_states, dim=-1)
else:# 获取投影矩阵W_Q,W_K,W_V
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
# 常规操作,为了并行将seq维度与head维度互换
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
past_key_value = getattr(self, "past_key_value", past_key_value)
cos, sin = self.rotary_emb(value_states, position_ids)
# 对Q K运用旋转矩阵
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_value is not None:
# sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
# 由于运用了GQA,所以需要重复,每4个Q公用一组KV
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
# 接下来的操作就与Attention的操作一模一样了
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
if attention_mask is not None: # no matter the length, we just slice it
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
attn_weights = attn_weights + causal_mask
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
if self.config.pretraining_tp > 1:
attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)])
else:
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value关于repeat_kv的实现如下,其实就是对KV进行复制,扩展成与Q的形状相同的tensor。
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
# 每一个Q共用一个KV,那就是MHA
if n_rep == 1:
return hidden_states
# 先扩展一个维度,让其在dim3上重复4次,先变成[bcz,head,1,seq,head_dim],然后expand成[bcz,head,4,seq,head_dim]
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
# reshape成[bcz,num_head,slen,head_dim],这样就与Q的维度相同了
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)RMSNorm
同上,用于归一化注意力模块的输出。
MLP
class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
#省略了在张量并行训练下的代码
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_projx会有两份,其中一份会经过一个门控信号,也就是gate_proj,在经过silu激活函数后与另一份经过升维操作的x进行哈达玛积。其中\(silu(x) =
x⋅σ(x)\),σ(x)是sigmoid函数。最后再进行降维。
RMSNorm
用于归一化LlamaMLP的输出。
Linear
本文以LlamaForCausalLM为例,所以在最后会输入一个Linear层得到logits,也就是潜在生成词的原始分数。
class LlamaForCausalLM(LlamaPreTrainedModel):
_tied_weights_keys = ["lm_head.weight"]
def __init__(self, config):
super().__init__(config)
self.model = LlamaModel(config)
self.vocab_size = config.vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False) # 此处